

Suppose you’re typing a question into the  Google search bar. You hit enter and get a list of the top relevant results within a second.
Google search bar. You hit enter and get a list of the top relevant results within a second.
 Ever wondered how Google understands your query in multiple languages?
Ever wondered how Google understands your query in multiple languages?
The answer lies in Google NLP algorithms (Natural Language Processing). These Google bot algorithms power your search, mobile apps, ads, translations, and more. In this blog, we’ll delve into the concept of what is NLP, Google NLP, how these algorithms work, & everything you must know about Google natural language processing model.
What Is Natural Language Processing?
Natural language processing (NLP) is a machine learning technology used in various fields, including computer science, linguistics, and artificial intelligence, to make the interaction between computers and humans easier. It is an element of artificial intelligence.
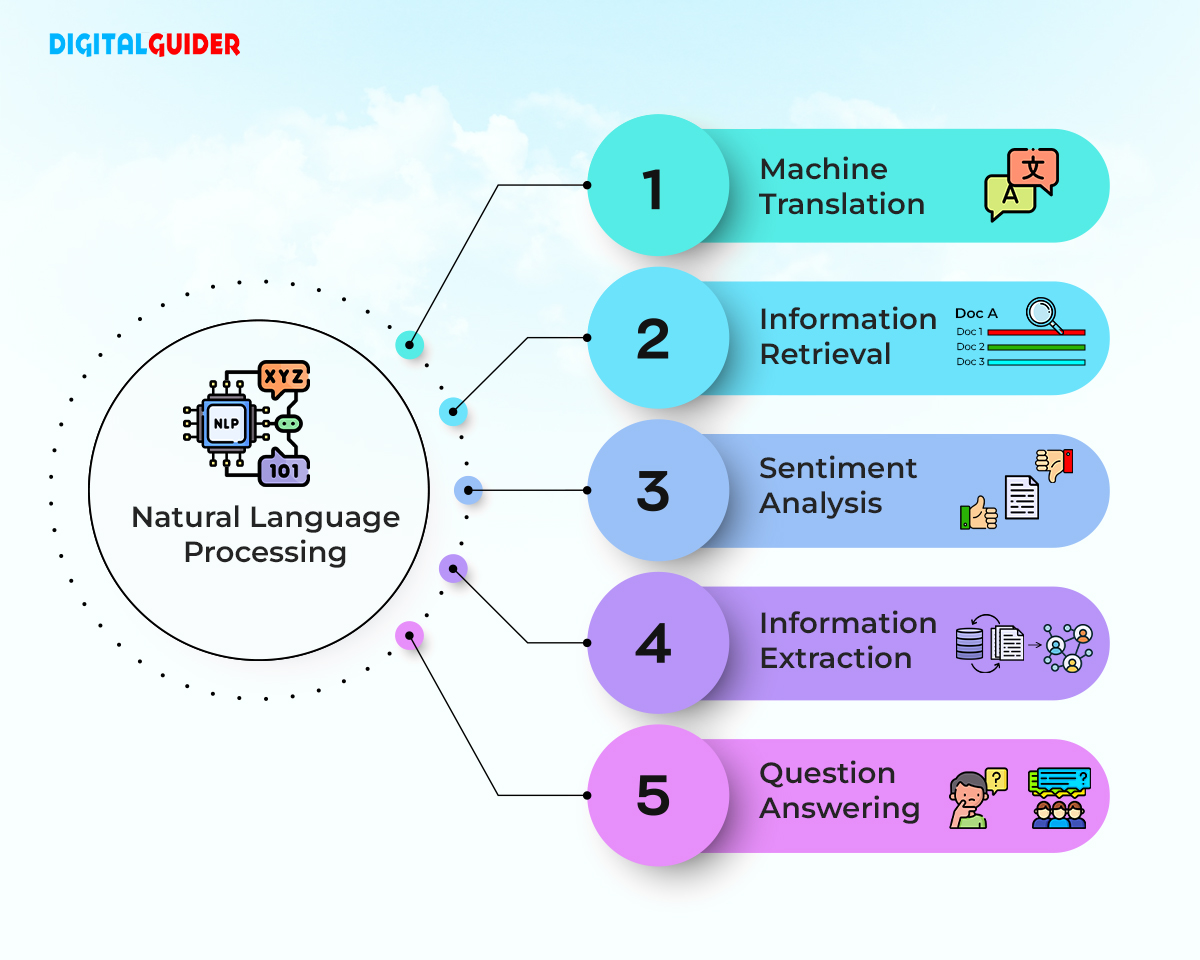
NLP machine learning has existed for more than 50 years & has roots in linguistics. Examples include machine translation, summarization, ticket classification, spell check, topic detection and tracking, speech recognition, and more. With NLP, computers can identify patterns and the context of the information, taking AI and computer science to the next level.
-
Core components of NLP
NLP tasks consist of various semantic and syntactic analysis tasks, which are used to comprehend the meaning of the text. The syntactic analysis focuses on identifying relationships between words. At the same time, semantic analysis is usually considered the more difficult section of NLP machine learning and focuses on recognizing the meaning of language.
– Content Type Extraction:
Identify a text’s content type based on structural patterns or context.
– Tokenization:
This task involves the semantical deconstruction of words referred to as tokens. Tokens are divided by blank spaces into terms. E.g., “Movers service in the USA receives many terrible customer complaints.” It can be simplified by word tokenization: “Movers service” “in” “the” “USA” “receives” “many” “terrible” “customer” “complaints.”
– Named Entity Analysis:
Identify words with known meanings and assign them to entity types (name, location, organizations, people, products, etc.). Example: “Leffe Beer is sold widely in the UK,” the name of the beer brand (Leffe Beer) is related to a place (the UK) by the semantic category “is sold widely in.”
– Part-of-speech tagging (PoS):
It involves labeling a specific speech group as a token of a text. Speech groups can include nouns, pronouns, adjectives, prepositions, and more. PoS is a tagging system that allows the computer to recognize word relations.
– Lemmatization:
Normalize word variations to their base form (e.g., “cars” to “car”). Lemmatization changes the text from “The mousetrap caught four mice yesterday” to “The mousetrap catch 4 mouse yesterday”. You can see the change in the words “caught,” “four,” and “mice.”
– Stemming:
Though it shares the definition with lemmatization holding up to the same word-reduction logic, it would not spot the connection between less and less. It takes one letter at a time without getting to the essence of the word.
– Identifying Implicit Meaning:
Recognizing implied meaning based on text analyzer structure, formatting, and visual cues.
– Word Type Labeling:
Classify words by their roles (object, subject, predicate, adjective, etc.).
– Text Classification:
It involves organizing text into categories using tags and making sense of the meaning of unstructured sentences.
– Parsing Labels:
Label words based on the relationship between dependent words. This visual task focuses on the terminal and non-terminal units elated to terms.
– Sentiment Analysis:
Identify the expressed opinion or attitude in a text.
– Morphological segmentation:
By breaking the words into smaller morphemes or units, segmentation extends its applications to speech recognition, data retrieval, machine translation, etc.
– Salience Scoring:
Determine the relevance of a text to a specific topic.
– Text Categorization:
Classify text into content categories.
– Word Dependencies:
Identify relationships between words based on grammar rules.
These components enable NLP machine learning to analyze and understand text, making it valuable for various applications, including NLP SEO, snippets, and E-E-A-T content classification.
What is Google NLP Algorithms?
Google NLP algorithms were designed to help better understand & process queries on its search engine as humans would. Elements of language like context, tone, phrasing, and specificity can be better processed using NLP machine learning frameworks.
Even though Google has been using NLP machine learning since 2011, only in 2019 was Google NLP integrated into the search engine. This algorithm was named BERT. Google Natural Language Processing (NLP) research focuses on algorithms that apply at scale across languages, & domains. The systems are used in numerous ways across Google, impacting user experience in search results, mobile apps, ads, translation, and more.
Note: NLP isn’t something that Google invented at first. But, later on, most AI language models Google developed, such as BERT, SMITH, and LaMDA, have Neural Network-based NLP (Machine Learning uses word embedding, sentence embedding, and sequence-to-sequence modeling for better quality results) as their brains.
BERT (Bidirectional Encoder Representations from Transformers) uses Google’s own Transformer NLP model based on Neural Network architecture. In layman’s terms, Google is not looking for individual content phrases but instead tries to find the context of the sentences to determine if it’s better than the results already ranking in the top positions.
Also Read: What Is Google Gemini AI – The End of ChatGPT Dominance?
Google BERT & Natural Language Processing (NLP)
BERT tries to understand natural language search & the relationship between each word through Masked-Language Modeling (MLM), wherein a few words within a query are used to generate possible & relevant answers, thereby self-transforming using the datasets it generates. It is used for multiple purposes like summarization, named entity recognition, translation, relationship extraction, speech recognition, and topic segmentation.
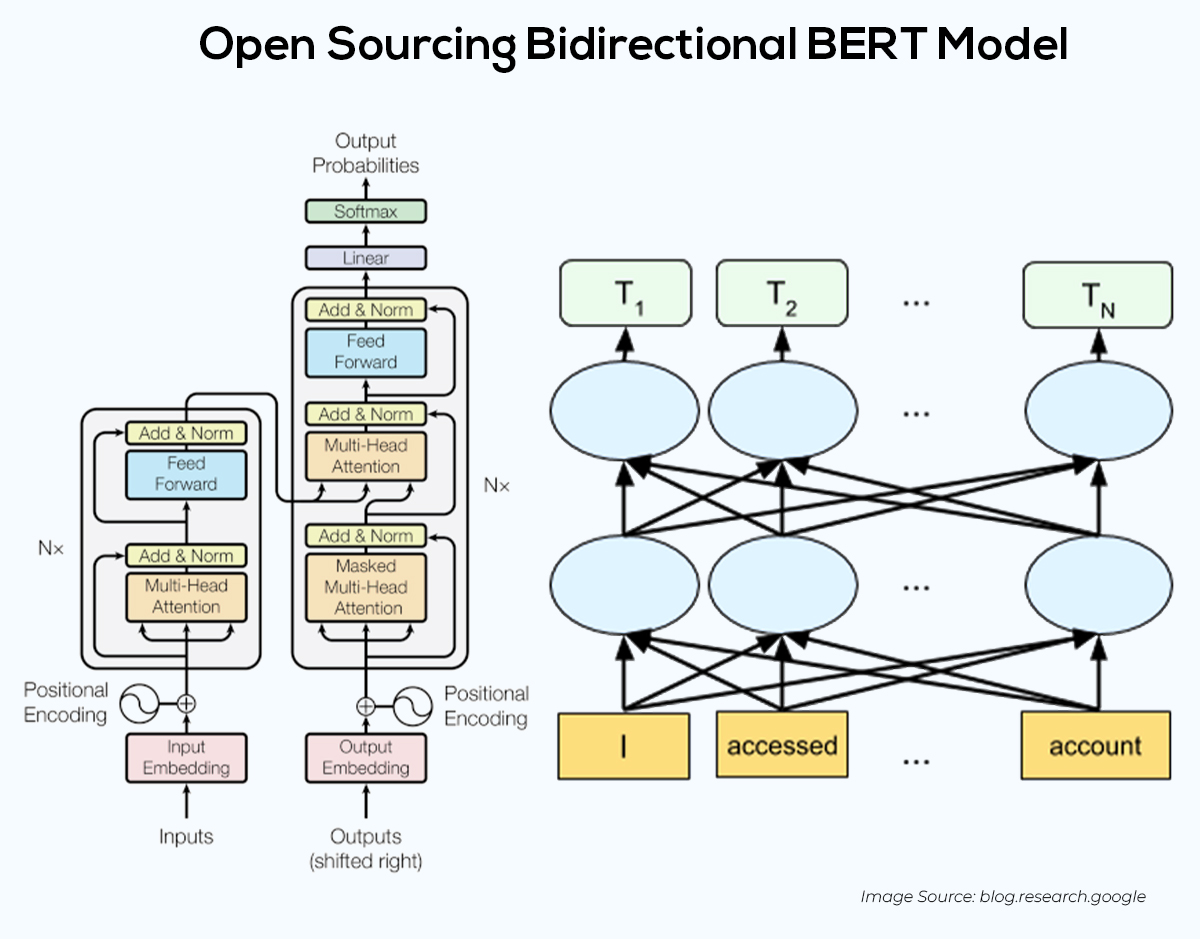
Image Source: blog.research.google (Open Sourcing Bidirectional BERT Model)
Google’s BERT algorithm is a breakthrough in the field of NLP. Most NLP models can only encode sentences in one direction, either left-to-right or right-to-left. But BERT’s bidirectional encoder looks at the target word in a sentence and considers all the surrounding words in both directions.
This allows BERT to understand a sentence’s context better and provide more relevant & accurate results. Google BERT improves its natural language search engine results and plans to use BERT to improve other Google services, such as Google Translate.
Also Read: What Is AutoGPT & How to Use It For Better Coding? The Ultimate Guide
How Google NLP Model Improve SERPs & Featured Snippets
For years, Google has trained AI language models like BERT to interpret text, natural language search queries, and video and audio content. These models are fed via NLP. Natural language processing plays a primary role in providing this knowledge repository. It interprets search queries, classifies documents, analyzes entities in documents and questions, generates featured snippets, NLP SEO, and understands video and audio content.
Google search mainly uses NPL in the following areas:
- Interpretation of natural language search result queries.
- Expansion and improvement of the knowledge graph/zero-click searches
- Entity analysis in search queries, documents, and social media posts.
- Classification of subject & purpose of documents.
- Interpretation of video and audio content.
- For generating featured snippets & answers in voice search.
Google highlighted the significance of understanding natural language searches when it released the BERT update in October 2019. 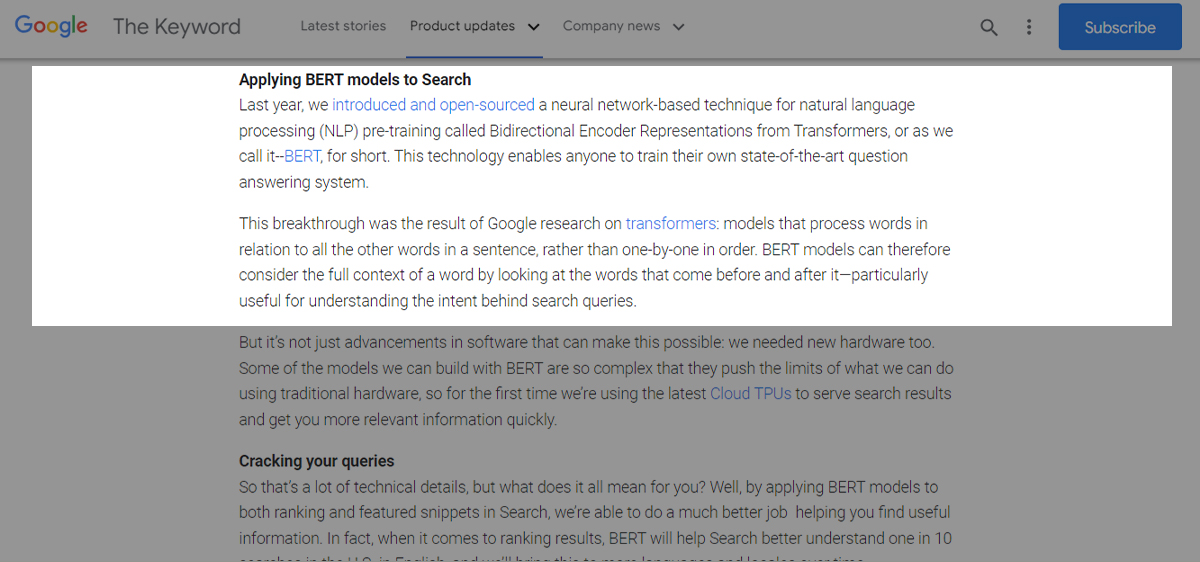
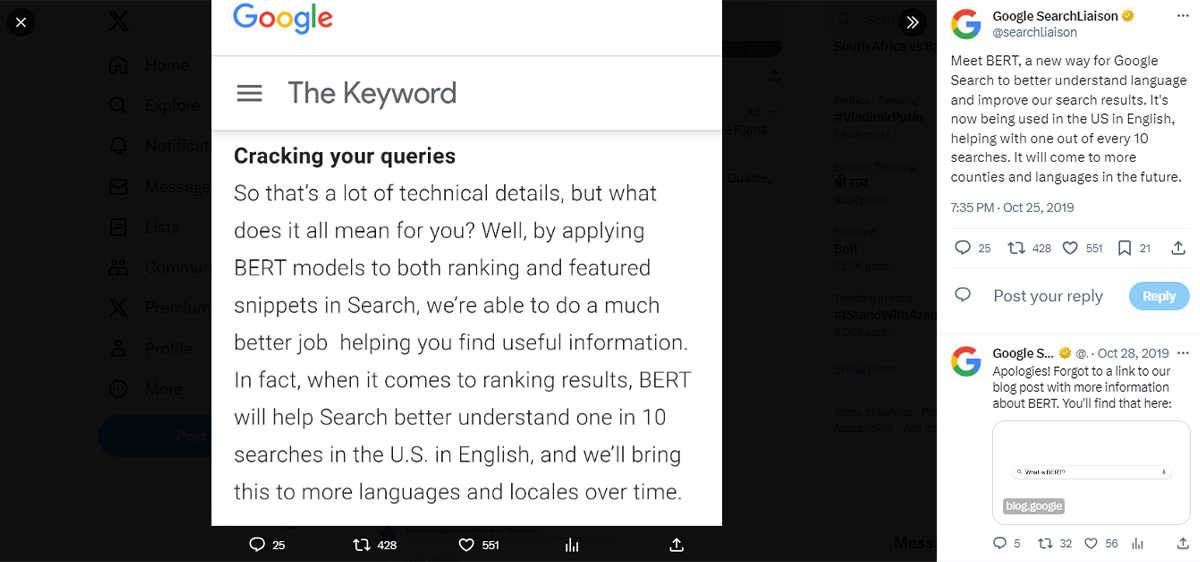
In the blog & platform X (Search Language Understanding BERT), Google mentions, “At its core, Search is about understanding language. It’s our job to figure out what you’re searching for and surface helpful information from the web, no matter how you spell or combine the words in your query. While we’ve continued to improve our language understanding capabilities over the years, we sometimes still don’t quite get it right, particularly with complex or conversational queries.”
-
Google NLP For Entity Mining
Natural language processing helps Google in entity mining and their meanings, making extracting knowledge from unstructured data possible. On this basis, relationships between entities & the Google knowledge graph can be created. The speech tagging feature partially helps with this. Nouns are potential entities; verbs often represent the relationship between entities. Adjectives describe the entity, and adverbs describe their relationship.
Google emphasizes implementing Structured Data Markup for the sites to help its algorithm recognize the entities based on unique identifiers associated with each. In cases where the Structured data or Schema is missing, Google has trained its bots/algorithm to identify entities with the content to help it classify, as you can see in the image analysis below.
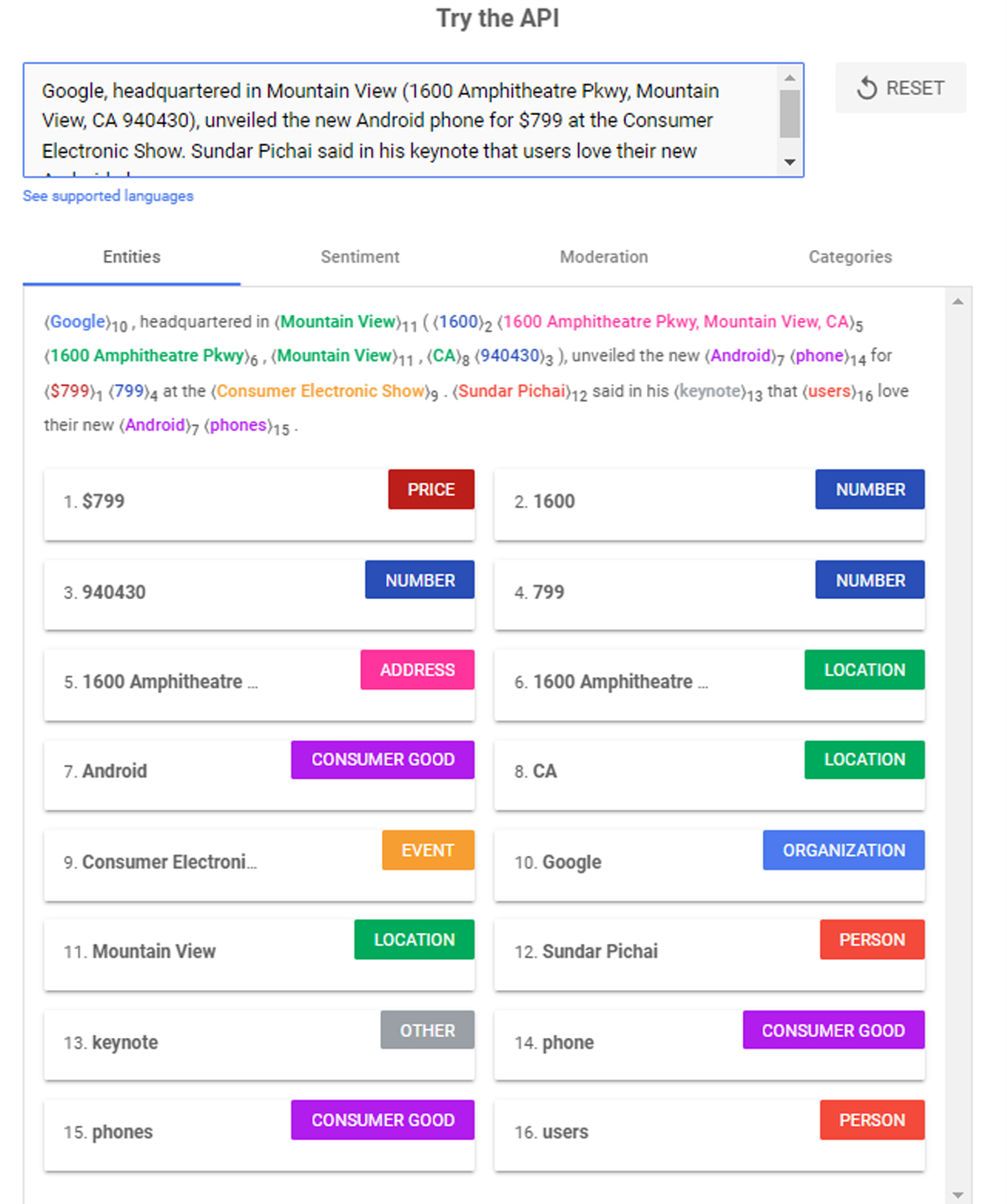
Once a user types in a query in a search bar, Google extracts or ranks these particular entities stored within its database after evaluating the relevance and context of the content.
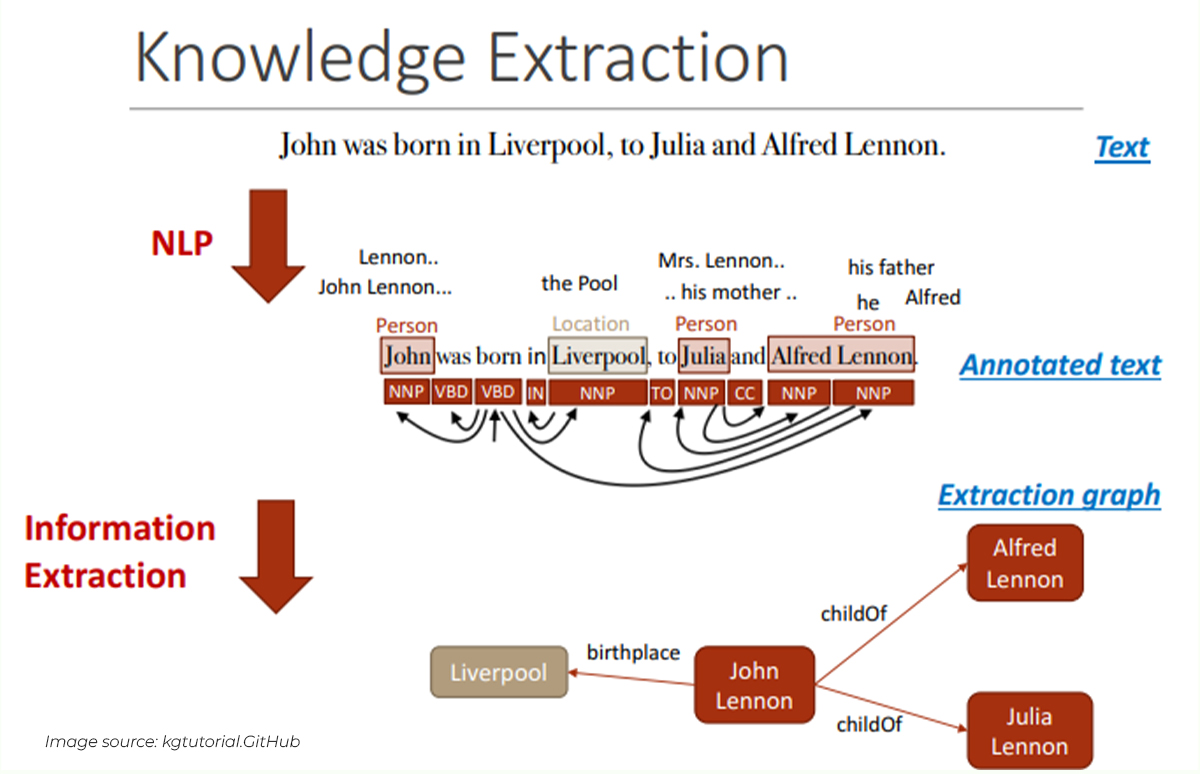
Image source: kgtutorial.GitHub
Google NLP/BERT plays a significant role in query interpretation, ranking and compiling quality featured snippets, NLP SEO, and interpreting text analyzer questionnaires in documents. Google is already quite good in NLP machine learning but has yet to achieve satisfactory outcomes in evaluating automatically extracted data as per accuracy. Data mining for knowledge graphs from unstructured data like websites is complicated. In addition to the completeness of the information, accuracy is essential & Google assures completeness at scale through NLP.
Also Read: How To Talk To ChatGPT? Everything You Need to Know
Final Words on Google Natural Language Processing
In short, Natural Language Processing has been a huge technological advancement, the methodology is a part of computer science, and AI has significantly changed the SEO industry. NLP allows computer systems to understand and comprehend human language deeply. NLP is Google’s (and many other companies’) approach to training its algorithms to better understand a page’s content and context by recognizing, categorizing, and classifying entities and their relationship to the user’s search questions. Want to get your business on top of SERPs by applying Google search engine tactics? Then get the best SEO services & check out our affordable SEO packages now.
The post How Google Uses NLP To Improve SERPs, Featured Snippets & UX appeared first on DigitalGuider.
Source: digitalguider.com


